SQL On Hadoop
SQL On Hadoop解决方案为用户提供关系模型和SQL查询接口,并透明的将SQL语句转化为Hadoop生态系统中的处理技术,此来管理和查询海量结构化数据。用户不需要额外去学习复杂的分布式计算框架(如MapReduce、Tez、Spark等),只需要将业务操作以SQL方式展示,降低用户学习成本。
三层模型:
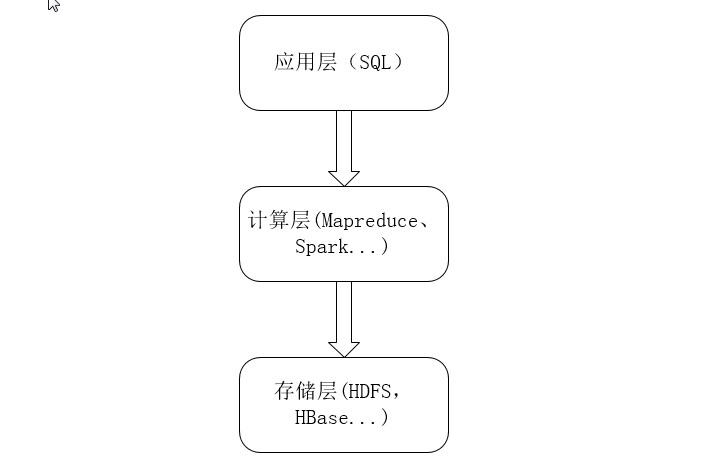
Hive
Apache Hive数据仓库软件可以使用SQL来帮助读取、写入和管理驻留在分布式存储中的大型数据集。
最早的SQL-on-Hadoop解决方案,Hive将SQL语句翻译成MapReduce程序,Apache 顶级开源项目
特点:
- 一种通过SQL语句访问数据的工具,支持数据仓库中的ETL、分析和生成报告任务
- 可以访问Hadoop HDFS上的文件和其它存储源如Hadoop HBase
- 使用 Tez、Spark、MapReduce作为SQL查询引擎
- 使用HPL-SQL语言
- 通过Hive LLAP、Apache Yarn、Apache Slider能够实现二次检索
目前的标准SQL是 ISO/IEC 9075 “Database language SQL”,最近更新时间为2016年,版本为:ISO/IEC 9075:2016
Hive支持部分标准SQL,具体参考: https://cwiki.apache.org/confluence/display/Hive/Apache+Hive+SQL+Conformance
Impala
- Impala是一个运行在Hadoop上的大规模并行处理(MPP)查询引擎
- Impala是一个实时SQL查询引擎,可快速查询Apache Hadoop HDFS和 HBase中的数据
- Impala提供与Hive相同的metadata、SQL语法、JDBC/ODBC驱动和用户接口,为批处理和实时处理提供了一个统一的平台
- Impala可在已存在的Hive表上执行交互式实时查询,大都能在几秒或几分钟内返回查询结果
- Impala默认使用Parquet文件格式
- Impala是一个Apache 开源项目,是Cloudera公司基于Google Dremel的开源实现
Presto
- Presto—分布式SQL查询引擎,主要针对GB和PB级的数据进行交互式分析查询。
- 目前,Facebook在300PB的集群中使用presto进行交互式分析查询。
- Presto是一个开源项目。
Spark SQL
Spark SQL——SQL查询引擎, 是 Apache Spark开源项目的一个模块,主要负责对结构化数据的处理。
- Spark SQL可以通过使用SQL语法或DataFrame API 对Spark中的结构化数据查询。
- Spark SQL可通过统一接口访问数据源,包括:Hive、Avro、Parquet、ORC、JSON、JDBC。
- Spark SQL支持HiveQL语法、Hive SerDes和UDFs,并可以访问Hive数据仓库。
- Spark SQL提供标准的JDBC/ODBC连接服务。
- Spark SQL可使用SQL查询Hive表