Delta事物日志分析
事务日志是理解Delta Lake的关键,因为它贯穿很多重要的功能,包括ACID事务、元数据的伸缩性和时间旅行等,所以接下来我们将详细分析下事务日志。
什么是事务日志?
Delta Lake事务日志(也称为DeltaLog)是自Delta Lake表创建以来已执行过的每个事务的有序记录。
事务日志应用在哪里?
1. 单事实源
Delta Lake建立在Apache Spark之上,允许同时在特定表上进行多个读写操作。 为了始终向用户显示正确的数据视图,事务日志作为单个事实源–中央存储库,跟踪用户对表所做的所有更改。
当用户第一次读取Delta Lake表或在已经打开的表中做新的查询时,但是其他用户对该表做了一些修改,Spark会检查事务日志以查看哪些新事务已发布到该表,然后使用这些新的事务更新最终用户的表。 这样可以确保用户的表版本始终与最近一次查询的主记录保持同步,并且确保当修改表有冲突是,用户不能对表进行事务提交。
2. 使用事务日志实现原子性
原子性是ACID事务属性之一,它确保对Delta Lake执行的操作(例如INSERT或UPDATE)要么全部完成,要么全部失败,防止因软硬件问题导致数据部分写入,引发数据混乱。
事务日志是如何工作的?
1. 将事务分解为原子提交
每当用户执行修改表的操作(例如INSERT,UPDATE或DELETE)时,Delta Lake都会将该操作分解为由以下一个或多个动作组成的一系列离散步骤。
- Add file – 添加一个数据文件;
- Remove file – 删除一个数据文件;
- Update metadata – 更新表的元数据(例如更改表的名称,模式或分区);
- Set transaction – Structured Streaming 作业已经提交的具有给定 ID 的微批次记录;
- Change protocol – 通过将事务日志切换到最新的软件协议来启用新特性;
- Commit info – 包含有关提交的信息以及该操作是在何时何地进行的;
然后这些操作将按照有序的原子单位记录在事务日志中,称为提交。
例如,假设用户创建一个事务以向表中添加新列,并向其中添加更多数据。Delta Lake 会将该事务分解为多个部分,一旦事务完成,就将它们添加到事务日志中,如下所示:
- Update metadata:更改表元数据以包含新列;
- Add file:每个添加的新文件。
2. 文件级别的事务日志
当用户创建Delta Lake表时,该表的事务日志会自动在_delta_log子目录中创建。 当对该表进行更改时,这些更改会按顺序记录在事务日志中,并且是原子提交。 每次提交都写到JSON文件中,最开始的文件为000000.json,对表的其他更改将按数字升序生成后续的JSON文件,因此下一个提交写为000001.json,然后是000002.json,依此类推。
![]()
接下来,我们举一个例子看下添加数据和删除数据时,事务日志是如何变化的。
假如,添加数据到两个文件1.parquet和2.parquet,则事务会自动添加事务日志,并保存到磁盘上(000000.json);接下来,我们删除这两个文件,并添加第三个文件3.parquet,这些行为会被写到事务日志中并提交保存到磁盘上(000001.json)
![]()
即使我们从表中删除了数据文件,Spark也不会立刻从磁盘中删除文件。 用户可以使用VACUUM删除不再需要的文件。
3. 使用Checkpoint文件快速重新计算状态
一旦我们对事务日志进行了10次提交,Delta Lake将以在_delta_log子目录中使用parquet格式保存checkpoint文件。 Delta Lake每10次(默认配置,可修改)事务提交会自动触发生成一个检查点文件。
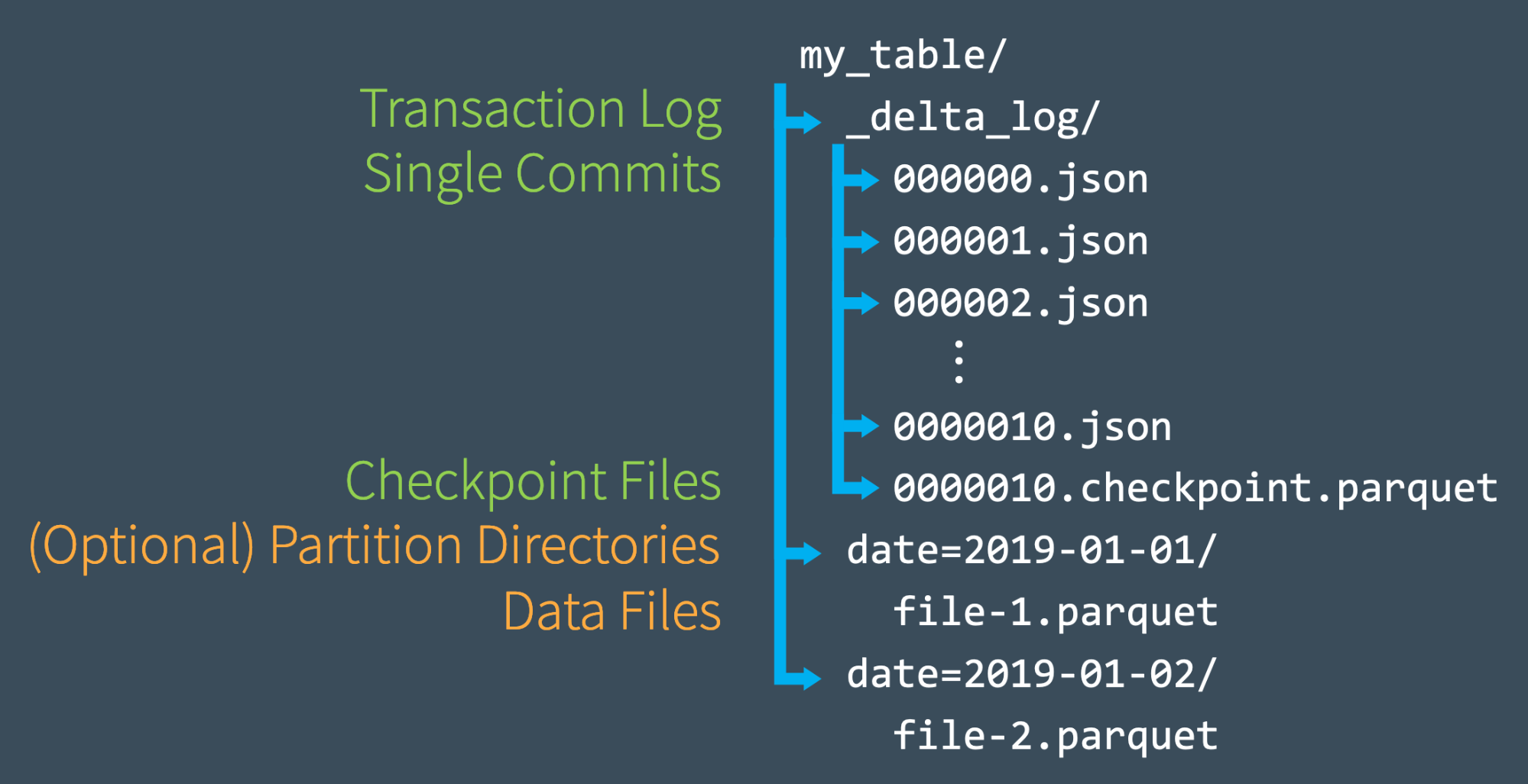 这些checkpoint文件会在某个时间点保存表的整个状态(使用Parquet格式保存),Spark可以轻松快速地读取它们,从而避免重新处理成千上万的JSON小文件。
这些checkpoint文件会在某个时间点保存表的整个状态(使用Parquet格式保存),Spark可以轻松快速地读取它们,从而避免重新处理成千上万的JSON小文件。
为了加快速度,Spark运行listFrom操作以查看事务日志中的所有文件,快速跳至最新的checkpoint文件,并且仅处理最新检查点文件之后所提交的JSON事务日志。
这里举个例子: 假如A commit了000007.json事务文件,Spark自动缓存当前版本为7,与此同时,用户B、C、D等提交了新的事务,目前最新版本为12(0000012.json)。A为了合并新的事务并更新表状态,从版本7开始运行listFrom查看对表新的更改。这时,Spark无需处理所有中间JSON文件,可以跳到最新的检查点文件(0000010.checkpoint.parquet),因为它包含提交版本7到版本10间表的整个状态。 现在,Spark只需执行0000011.json和0000012.json的增量处理即可获得表的当前状态。 然后,Spark将表的版本12缓存在内存中。 通过遵循此工作流程,Delta Lake可以使用Spark始终高效地保持表状态的更新。

4. 多并发读/写处理
到目前为止,我们的示例大部分涵盖了用户没有冲突地提交事务的场景。 但是,当Delta Lake处理多个并发读写时会发生什么呢?
答案很简单。 由于Delta Lake由Apache Spark提供支持,因此,不仅可以让多个用户一次修改表,而且结果还可以预期。 为了处理这些情况,Delta Lake采用了乐观并发控制。
5. 什么是乐观并发控制?
乐观并发控制是一种处理并发事务的方法,该方法假定不同用户对表进行的事务(更改)可以完成而不会相互冲突。速度之快令人难以置信,因为在处理PB级数据时,用户极有可能会完全处理数据的不同部分,从而使他们能够同时完成无冲突的事务。
例如,假设您和我正在一起研究拼图游戏。只要我们都在其中的不同部分上工作(例如,您在角落,而我在边缘),就没有理由为什么我们不能同时为更大难题做一部分工作,并以两倍快的速度完成拼图。只有在我们需要相同的零件的同时,才存在冲突,这就是乐观的并发控制。
相比之下,某些数据库系统采用了悲观锁的概念,这种假设被认为是最坏的-即使我们有10,000个拼图,但在某个时候我们肯定会需要相同的拼图-会引起太多冲突。为了解决这个问题,它的理由是只允许一个人同时从事拼图游戏,并将其他所有人锁在房间之外。这不是快速(或友好)解决难题的方法!
当然,即使使用乐观的并发控制,有时用户也确实会尝试同时修改数据的相同部分。幸运的是,Delta Lake对此有一个协议。
6. 乐观地解决冲突
通常,该过程如下:
- 记录起始表版本;
- 进行读/写操作;
- 尝试提交;
- 如果其他人已提交,请检查你读到的内容是否已更改;
- 重复上面步骤;
为了了解这一切是如何实时进行的,让我们看一下下面的图表,看看 Delta Lake 在冲突突然出现时是如何管理冲突的。假设两个用户从同一个表中读取数据,然后每个用户都尝试向表中添加一些数据。
- Delta Lake记录在进行任何更改之前读取的表起始版本(版本0)。
- 用户1和2都尝试同时将一些数据追加到表中。 在这里,我们遇到了冲突,因为接下来只能进行一次提交并将其记录为000001.json。
- Delta Lake通过“互斥”的概念解决了这一冲突,这意味着只有一个用户可以成功提交000001.json。 此时,接受用户1的提交,而拒绝用户2的提交。
- Delta Lake使用乐观方式处理此冲突,避免User 2抛出异常。 它检查是否对该表进行了任何新提交,并以静默方式更新该表以反映这些更改,然后只需在新更新的表上重试用户2的提交(不进行任何数据处理),即可成功提交000002.json。

在绝大多数情况下,这种和解是悄无声息地、天衣无缝地、成功地进行的。但是,如果 Delta Lake 无法乐观地解决不可调和的问题(例如,如果用户1删除了用户2也删除的文件),那么惟一的选择就是抛出一个错误。
最后要注意的是,由于在Delta Lake表上进行的所有事务都直接存储到磁盘中,因此这个过程满足 ACID 持久性的特性,这意味着即使在系统发生故障时,它也会保证数据不会丢失。
总结
Delta Lake事务日志是面向文件层面,利用文件系统的功能(写前,检查事务文件是否存在)作为事务冲突检测方法,加上重试机制,达到乐观并发控制能力。但是随着事务的不断发生,事务数据会越来越多,需要在事务日志上计算花费的时间也将增大。
接下来,会对Delta事务源码进行分析,可以期待下。